Pull down six tasks.
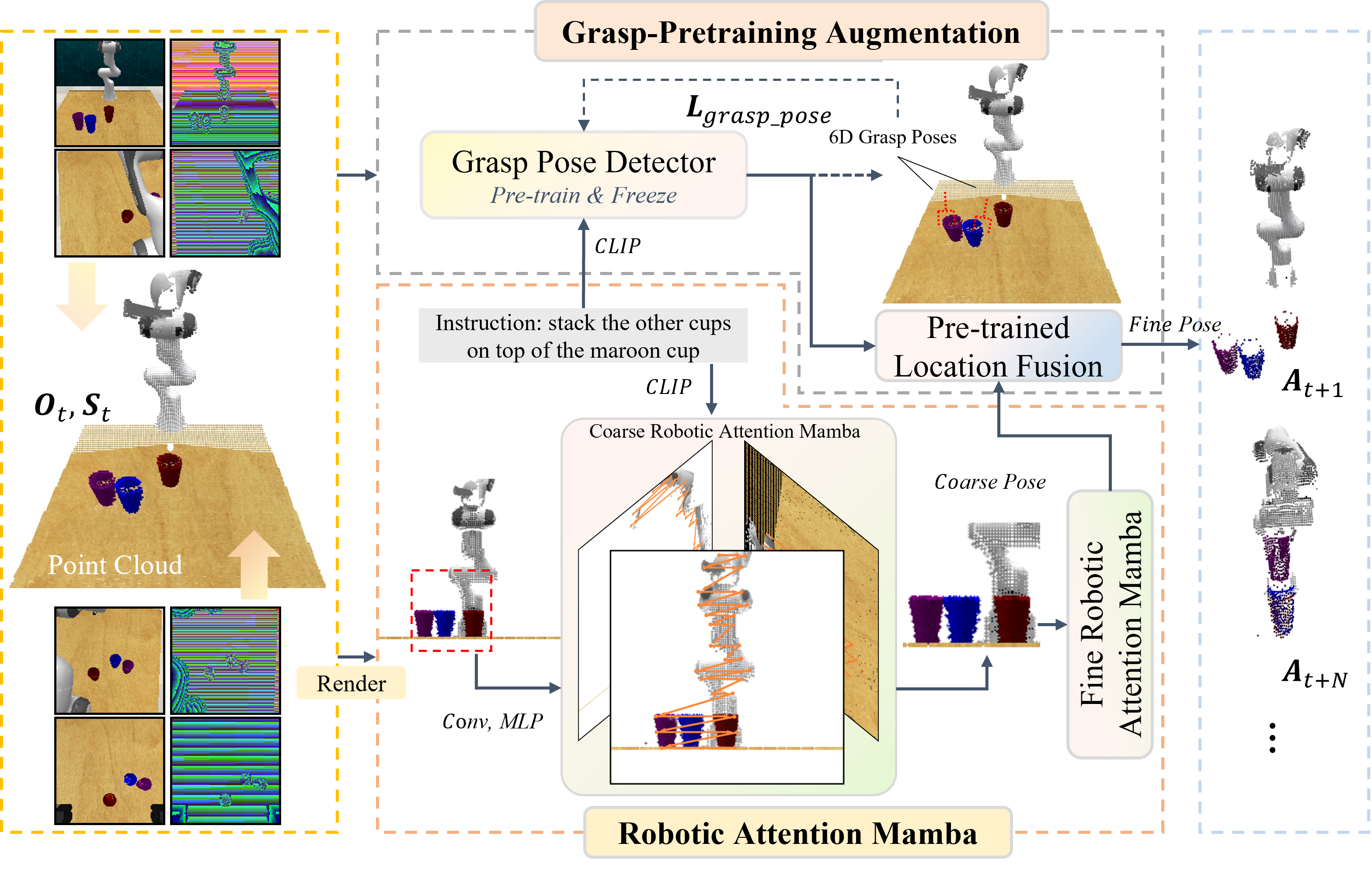
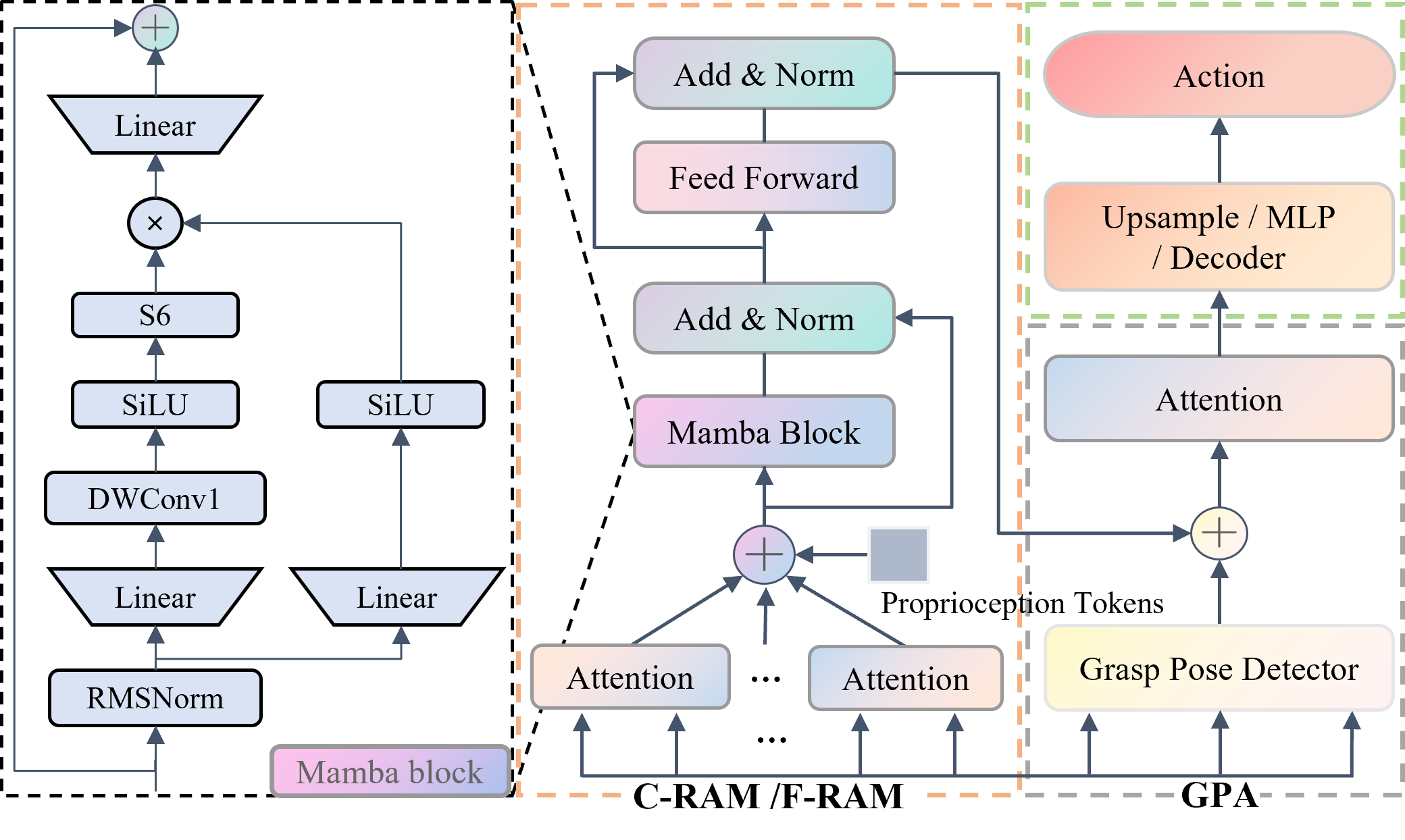
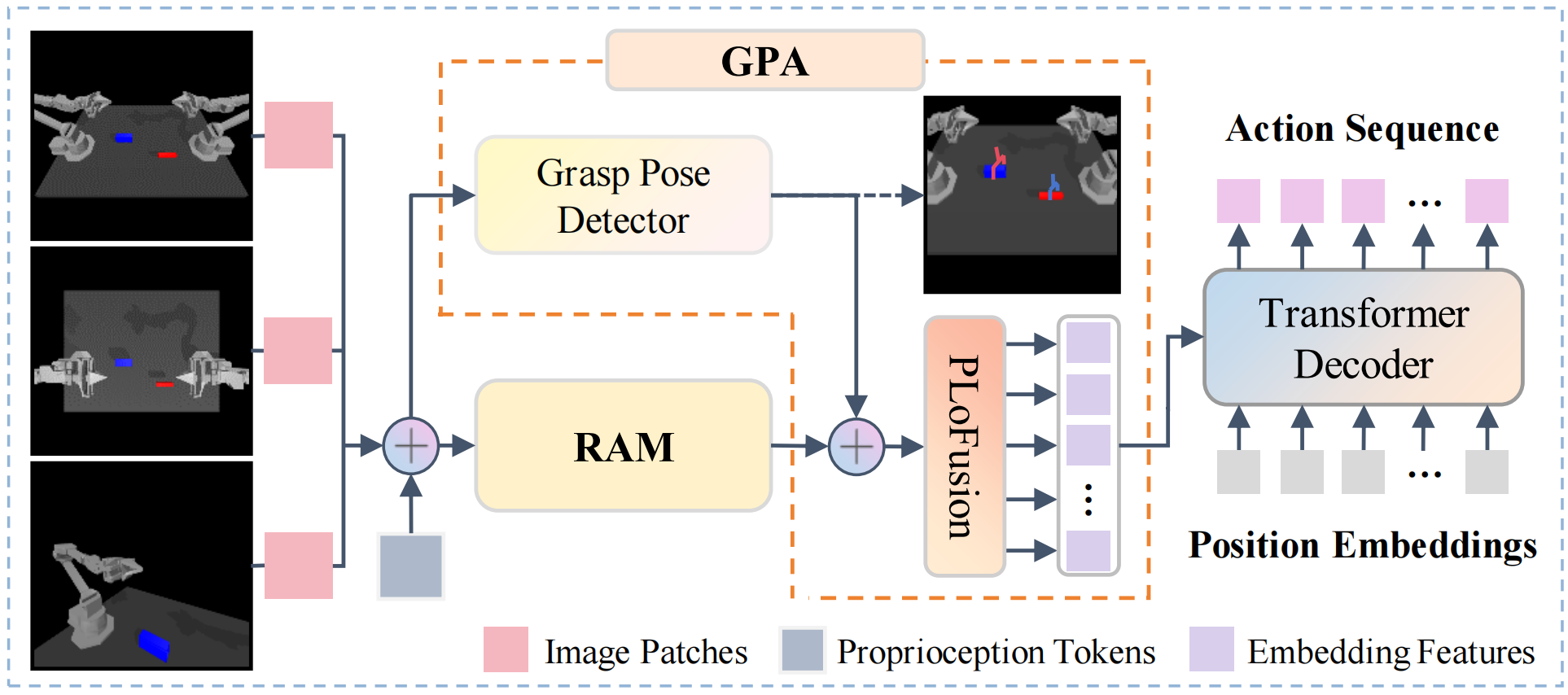
Task failures in prior fine-grained robotic manipulation methods often stem from suboptimal initial grasping, which is critical for subsequent manipulation and reducing complex pose adjustments. To address this, we propose Grasp-Pretraining Augmentation (GPA)—a general learning framework that enhances grasp perception without additional grasp pose data collection and labeling. GPA achieves evident enhancement on RLBench multi-task benchmark (from 79.3% to 84.2%) and ALOHA bimanual manipulation tasks (from 86%/16% to 98%/38%). Although GPA enhances fine-grained grasping performance by leveraging increased model capacity, it incurs high computational latency, hindering real-time deployment. To mitigate this limitation, we introduce Robotic Attention Mamba (RAM). This novel architecture synergizes attention mechanisms with state space models (SSMs), effectively capturing complex spatial features while maintaining superior inference efficiency. We integrate GPA and RAM into a unified framework, GPA-RAM, which balances model capacity with efficiency and applies to both discrete and continuous action generation. GPA-RAM demonstrates superior performance across four robotic systems with diverse camera configurations in both simulation and the real world. Compared with previous state-of-the-art methods, it improves average success rates by 8.2% over RVT2 (from 79.3% to 87.5%) and 2.6% over ARP+ (from 84.9% to 87.5%) on RLBench and 40% (from 16% to 56%), 12% (from 86% to 98%) on ALOHA tasks, while maintaining high inference speed. Furthermore, sufficient experiments and ablations demonstrated that GPA and RAM are both generic and applicable to different end-to-end network architectures and task settings.
Pull down six tasks.
Pull down six tasks.
Pull down six tasks.
Aloha dataset.
Aloha dataset.
[Transfer Plate]
[Tabletop Organization]
[Stack Bowl]
Different real world tasks results.